Expériences & Réalisations
Foliateam - OpenMeetings
Avril - Juin 2011 at Foliateam, Saint-Maurs-des-Fossés
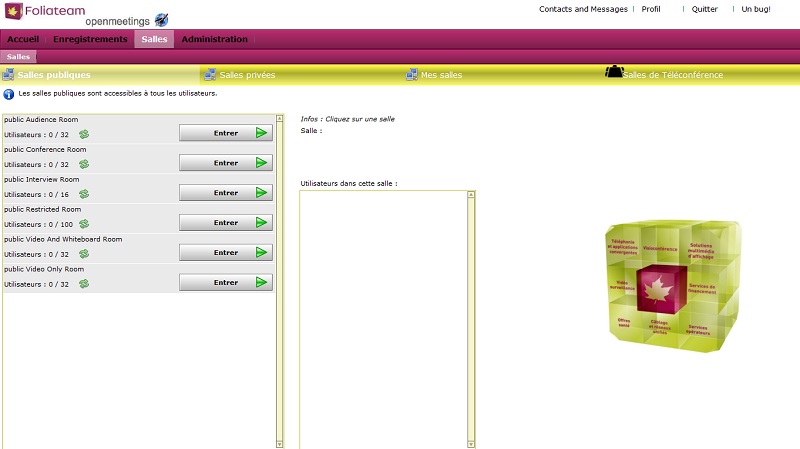
Fruit de mon stage de fin d'étude DUT au sein d'une société spécialisée en Télécommunication et sécurité, la plateforme OpenMeetings est une solution de webconfrencing basée sur un serveur RED 5 et implémentée en OpenLazslo. C'est à partir de cette solution open source que j'ai dû élaborer un module complémentaire permettant de concilier l'univers webconferencing PC avec les solutions traditionnelles de téléprésence en salle type Polycom, le tout via le protocol SIP!
\r\n\r\n
solution OpenMeetings
Hélàs, suite à de nombreuses contraintes (essentiellement de temps), je n'ai pas pu venir à terme de ce projet ambitieux. Au final, j'ai réussi à maîtriser les concepts de base de la programmation OpenLazslo (qui est un langage donnant de beau résultat graphique) et à réaliser une adaptation de la charte graphique d'OpenMeetings à l'image de Foliateam! En outre, je maîtrise mieux OpenMeetings si certains ont besoin d'aide la dessus.
\r\nsite web de l'entreprise d'accueil, Foliateamsolution OpenMeetings
Anti-Plagiat
Mars - Avril 2011 at IUT Paris 13, Villetaneuse
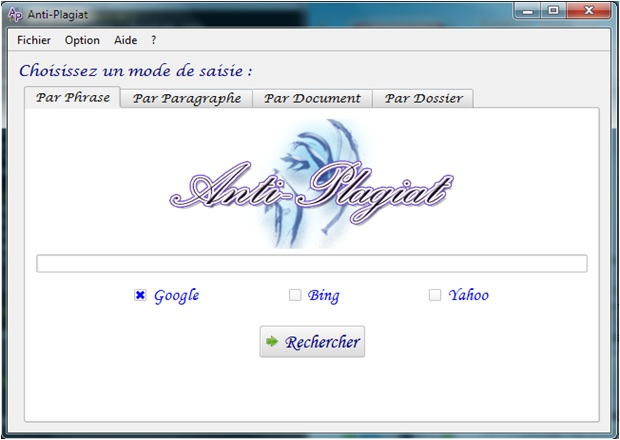
A l'issu de mon projet de fin d'étude, j'ai été en charge en tant que chef de projet de gérer une équipe de 4 personnes. C'est ainsi que vit le jour quelques semaines plus tard le logiciel d'anti-plagiat après différentes phases de développement rigoureusement suivies (spécification, conception, développement, déploiement). Ce projet fut pour moi l'un des plus délicats à aborder de par le fait qu'il nécessita une coordination des ressources humaines suivant une planification judicieusement élaborée, un va et vient constant entre le client et l'équipe de développement...
\r\n\r\n
\r\n
\r\nDéveloppé en C++ via le framework Qt, l'application propose plusieurs mode de détection (par phrase, par paragraphe...) et son interface est multilingues. Plus de détails et l'application en téléchargement libre en suivant les liens suivants:
\r\n\r\n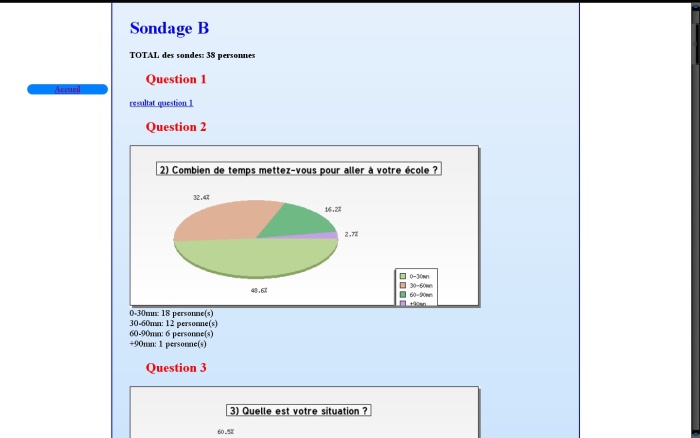
Artichow
déc 2010 at Projet Personnel, Redakle
Non, je ne vais pas vous parler des artichauts et de l’amour que je voue à ce légume…..hum hum Artichow est en réalité une librairie graphique pour le dessin en php que j’ai utilisé pour le traitement des données recueillies par un sondage.
\r\n\r\n
\r\n
\r\nCet outil très pratique m’a donc permis de tracer dynamiquement des camenberts, des histogrammes… au fur et à mesure que des personnes répondaient au sondage. Un conseil cependant : à moins d’être aussi dérangé que moi, préféré Google Docs pour faire un sondage à l’avenir, c’est clairement plus rapide qu’un travail maison!!!
\r\n
SecureTime v2
dec. 2010 at Projet personnel, Redakle
Le jour et la nuit : that’s the difference! Même objectif, proposer un outil de gestion de temps d'accès, mais conception radicalement différente ! Relooking complet de l’interface graphique, allégement monstrueux de la complexité du code, conception rigoureuse suivant le modèle MVC (modèle-vue-contrôleur, que je venais de découvrir) avec, au final, que du bonheur!
\r\n\r\n
\r\n
\r\nCette seconde révision de SecureTime représentait, selon moi, un programme correctement implémenté: seules lacunes, l'absence de spécifications, de versionning des codes ou de méthodologie de projet (du type développement en V par exemple).
\r\n